*본 글은 개인적으로 헷갈리거나 정리하고 싶은 것을 블로그에 타이핑 필기하는 용도로 작성
*오타가 있을 수 있음 / *사용한 책 : 이기적 빅데이터분석기사 실기 기본서(2022)
빅데이터 분석기사 실기 독학 ① - R 프로그래밍 기초 : https://masami.tistory.com/15
빅데이터 분석기사 실기 독학 ② - R로 데이터 다루기 : https://masami.tistory.com/16
빅데이터 분석기사 실기 독학 ③ - 데이터 탐색 : https://masami.tistory.com/17
데이터 전처리 : 데이터 가공, 데이터 핸들링으로 불리며, 원시적인 형태의 데이터를 내가 원하는 형태로 변환하는 과정
- 데이터의 수집 목적과 다르게 사용하려면 데이터 전처리 과정 필요
- 데이터에 틀린값이 들어갔거나, 빠져있거나, 단위가 틀리는 등의 문제를 조정해야 함
- 데이터가 처리하기 좋은 형식으로 되어 있는지, 데이터를 새로 가공해야 하는지 등을 파악해야 함
rnorm() : 난수 발생 함수 => rnorm(n, mean=k, sd=s)
: 평균 k, 표준편차 s, 정규분포를 따르는 n개의 난수를 생성
hist() : 히스토그램 함수 => hist(x, breaks="Sturges", freq=TRUE, main="title")
- 데이터의 빈도를 breaks에서 정의한 구간의 히스토그램으로 표현
- x : 히스토그램의 대상 / breaks : 히스토그램 계급구간, 기본값 Sturges는 n일때 막대의 너비를 log2(n)+1로 정함
- freq : TRUE면 실제 빈도수 표시, FALSE면 상대 빈도수(비율) 표시 / main : "테이블명" 그래프 제목
scale() : 스케일 함수
=> scale(x, center=TRUE, scale=TRUE) -> z-표준화
=> scale(x, center=Min, scale(Max-Min)) -> Min-Max 정규화
- 행렬 유형의 데이터를 정규화
- x : 숫자 벡터 유형의 객체
- (z-표준화) scale=TRUE, center=TRUE : 모든 데이터를 전체 데이터의 표준 편차로 나눔
- scale=TRUE, center=FALSE : 모든 데이터를 전체 데이터의 제곱평균제곱근으로 나눔
- scale=FALSE : 데이터를 어떤 값으로도 나누지 않음
- Min : 최솟값 / Max-Min : 최댓값 - 최솟값
+ z 표준화 또다른 방법 : (x-mean(x))/sd(x) 식을 직접 입력하여 표준화
+Min-Max 정규화의 또다른 방법 : (X-Min)/(Max-Min) 식을 직접 입력하여 표준화
왜도 계산 및 변환

*왜도 계산을 위해 "moments" 패키지 설치 후 진행
skewness(df$변수, na.rm=TRUE) -> 왜도 계산 함수
log(df$변수) : 변수를 로그변환 / log10(df$변수) : 변수를 로그변환(단 log10 으로 변환)
정규화 변환의 요령
- 독립변수 값이 증가함에 따라 종속변수가 더 빠르게 증가하기 시작하는 상황에서는 로그변환을 시도
- 데이터가 반대인 경우 독립변수 값이 증가함에 따라 종속변수 값이 더 빠르게 감소하는 경우 먼저 제곱 변환을 시도
- 로그 변환을 사용할 때는 변환 전 모든 값을 양수로 만들기 위해 모든 값에 상수를 추가
범주화, 이산형화 : 연속형 변수를 범주형 변수로 변환하는 작업
cut() 함수 => cut(변수, breaks = c(0,10,20,30), include.lowest=TRUE, right=FALSE, labels=c("A","B","C","D"))
- right=TRUE : a<x<=b / right=FALSE : a<=x<b
- include.lowest=TRUE : 구성요소 값이 최솟값과 같아도 변환시킴
ifelse()함수 : test가 참이면 yes에 해당하는 값을, 거짓이면 no에 해당하는 값을 반환
within()함수 : 데이터를 수정하는 기능 제공
PCA 분석 수행 : prcomp() 함수 사용 =>prcomp(df, center=TRUE, scale=TRUE)
- center와 scale을 TRUE로 해서 표준화 해줘야 변수 간의 단위 차이를 없앨 수 있다
- 투입된 변수가 4개이면, 주성분도 4개까지 생성됨
- 결과에 보이는 수치는 각 변수가 각각의 주성분에 기여한 정도를 보여줌

결측치 확인 함수 : is.na() -> 결측치인 경우 TRUE 반환하고, 값이 존재하는 경우 FALSE 반환
+sum(is.na(df)) : 데이터셋 전체에서 결측치의 수를 보여줌
결측값이 들어있는 벡터에 대해 통계 함수를 적용하면 NA만 나옴
-> 결측값을 포함하지 말고 통계 함수 계산을 하는 옵션은 na.rm=TRUE
=> sum(df$변수, na.rm=TRUE) : 결측값 포함하지 말고 변수의 합 산출

na.omit() : 결측값이 들어있는 행 전체를 데이터 셋에서 제거
complete.cases(x) : x(벡터행렬, 데이터프레임)-> 결측치가 없으면 TRUE, 결측치 있으면 FALSE로 반환
- Age 컬럼 내 결측값이 있는 행 제거

dataset$var[is.na(dataset$var)]<-new_value 형식으로 결측치를 대체
: 결측치를 찾아내고 해당 결측치를 new_value로 대체
- new_value 대신 mean(dataset$var, na.rm=TRUE)를 넣어 평균값으로 대체 가능
group_by()함수를 사용하여 그룹별 Age 평균 구하기

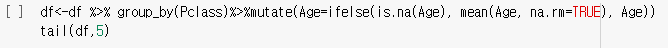
이상치 처리 - IQR 방법

boxplot을 그렸을 때, 점으로 나오는 샘플들이 바로 IQR Rule에서 말하는 outlier들
: 데이터들이 정규분포를 그린다고 가정하였을 때 사용 가능
fivenum() : 데이터를 최솟값, 제1사분위수, 중앙값, 제3사분위수, 최댓값의 다섯 가지 수치로 요약
summary() : 다섯수치 요약에 더해 평균까지 계산
quantile() = fivenum() (단 quantile는 퍼센트와 그 값을 알려주고(0% : 2) fivenum은 값만 알려줌(2 )
'R' 카테고리의 다른 글
| 빅데이터 분석기사 실기 독학 ③ - 데이터 탐색 (0) | 2022.06.18 |
|---|---|
| 빅데이터 분석기사 실기 독학 ② - R로 데이터 다루기 (0) | 2022.06.18 |
| 빅데이터 분석기사 실기 독학 ① - R 프로그래밍 기초 (0) | 2022.06.18 |
| R 기초 ② - 패키지 설치 (0) | 2021.12.25 |
| R 기초 ① - 데이터 입력, 평균, 분산, 표준편차 함수 (0) | 2021.12.18 |



